当代外语研究 ›› 2024, Vol. 24 ›› Issue (3): 96-109.doi: 10.3969/j.issn.1674-8921.2024.03.010
刘晓宇( )
)
LIU Xiaoyu()
摘要:
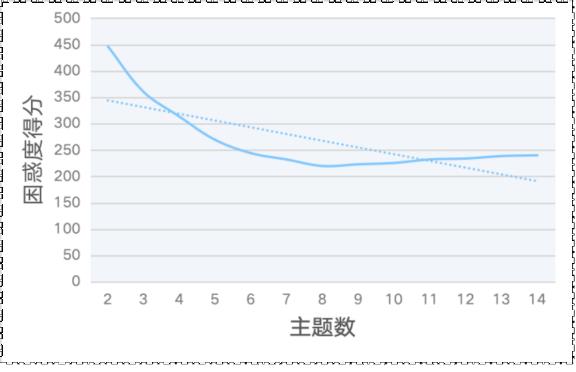
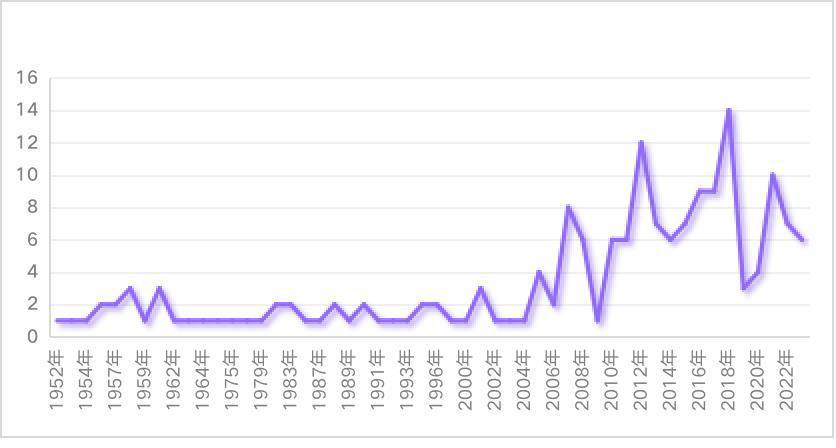
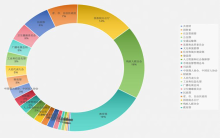
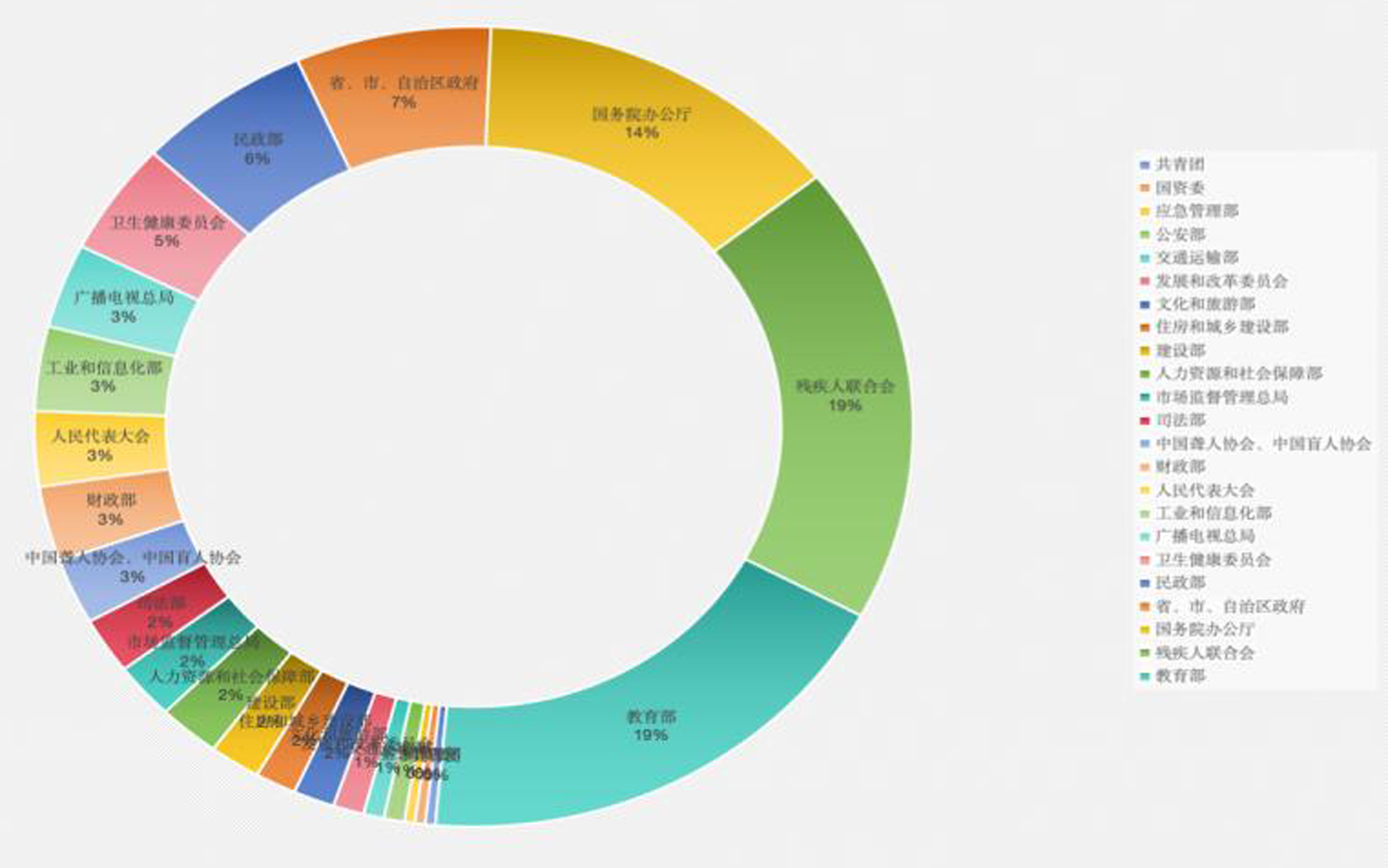
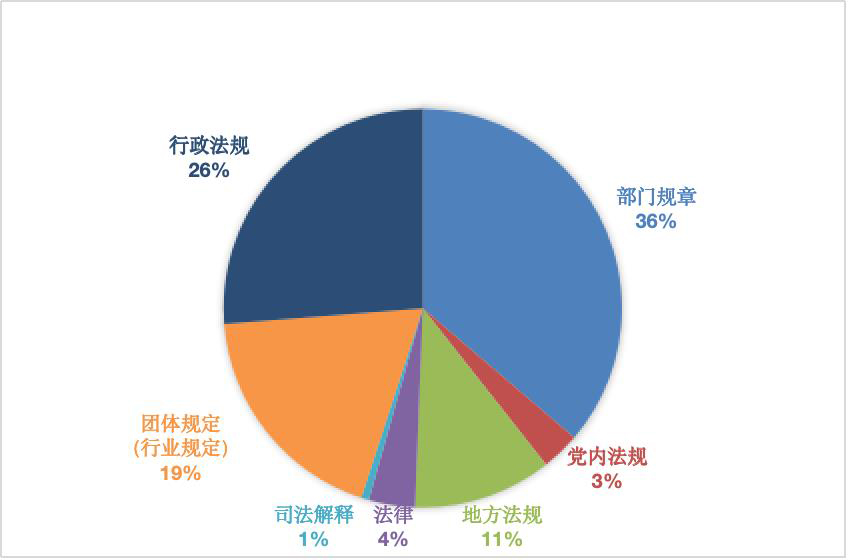
语言障碍群体的语言政策是中国语言文字事业发展的重要议题之一,厘清中国语言障碍群体的语言政策布局,对于应对其语言问题具有纲领性作用。本研究依托北大法宝数据库,创建了中国语言障碍群体的语言政策语料库,归纳中国语言障碍群体的语言政策文本整体特征。通过基于Python的自然语言处理方法,采用LDA主题模型和TF-IDF算法,从时间与空间维度深入分析中国语言障碍群体的语言政策文本。研究主张加强顶层设计,整合语言政策体系;统一称谓,推动社会理念转变;构建语言政策反馈渠道,切实服务语言障碍群体。本研究尝试为完善语言障碍群体的语言政策体系以及构建信息无障碍社会提供参考。
中图分类号: